
What's New in Gemma 3: The Ultimate Guide to Google’s Multimodal AI Powerhouse

Since its debut, the Gemma open-model family has revolutionized the AI landscape, amassing over 100 million downloads and inspiring the community to create 60,000+ model variations for diverse applications. Today, Google unveils Gemma 3, the most advanced iteration yet, designed to redefine what compact AI models can achieve. With groundbreaking features like multimodality, 128k-token context windows, and 140+ language support, Gemma 3 empowers developers to build smarter, safer, and more versatile AI solutions.
In this comprehensive guide, we’ll explore:
- What’s new in Gemma 3 (and why it matters).
- The technical innovations behind its development.
- How ShieldGemma 2 ensures responsible AI usage.
- Real-world applications from the Gemmaverse community.
- Step-by-step resources to start building with Gemma 3 today.
What’s New in Gemma 3? Breaking Down the Upgrades
Gemma 3 isn’t just an incremental update—it’s a leap forward. Here’s what sets it apart:
1. Multimodality: Vision Meets Language
For the first time, Gemma 3 supports vision-language inputs, enabling it to process images, videos, and text in tandem. This means:
- Image analysis: Identify objects, answer questions about visuals, or compare multiple images.
- Text extraction: Read and interpret text within images (e.g., road signs, manuals).
- High-resolution support: An adaptive window algorithm processes non-square images up to 896x896 pixels.
Example Use Case:
A user uploads a photo of a thermostat and asks, “How do I turn up the heat?” Gemma 3 analyzes the image, detects the 暖房 (heating) button, and explains its function—all in natural language.
2. Expanded Context & Language Mastery
- 128k-token context windows: Process lengthy documents, codebases, or multi-hour conversations without losing coherence.
- 140+ languages: From Bulgarian to Bahasa Indonesia, Gemma 3’s new tokenizer enhances multilingual fluency.
3. Enhanced Reasoning & Structured Outputs
Gemma 3 shines in math, coding, and instruction-following, thanks to:
- Structured outputs: Generate JSON, XML, or custom formats for seamless API integration.
- Function calling: Execute code snippets or external tools mid-response.
4. Four Sizes, Infinite Possibilities
Choose from four model sizes (1B, 4B, 12B, 27B) tailored for different needs:
- 1B: Lightweight, ideal for mobile or edge devices.
- 27B: High-performance for complex enterprise tasks.
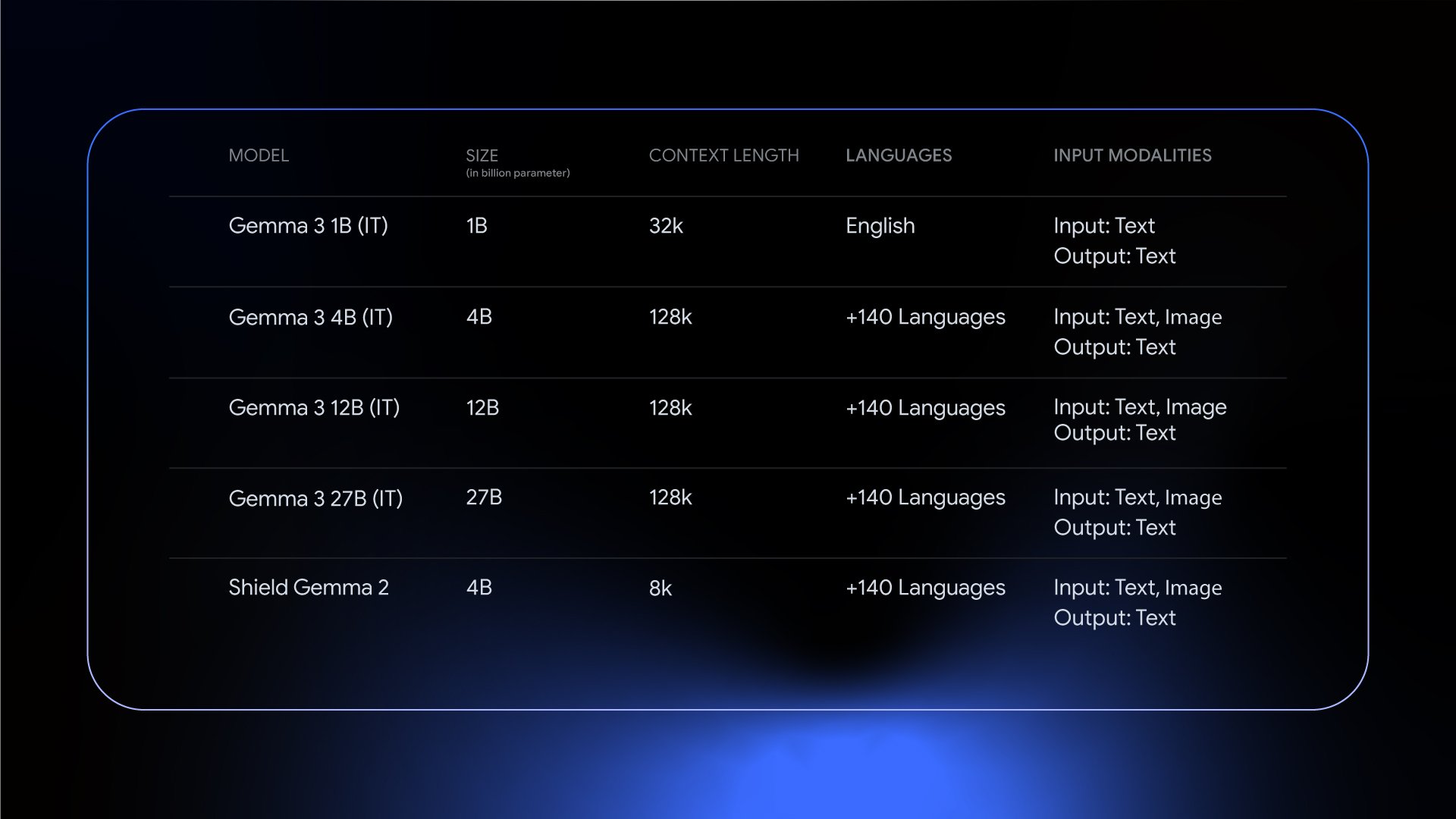
Gemma 3’s size variants balance speed and capability.
Under the Hood: How Gemma 3 Was Built
Gemma 3’s prowess stems from Google’s innovative training pipeline:
Pre-Training: Scale Meets Efficiency
- Token counts: 2T (1B) to 14T (27B) tokens trained on Google TPUs via JAX.
- SigLIP Vision Encoder: A frozen vision model processes images uniformly across all sizes.
Post-Training: The Reinforcement Trio
- Distillation: Knowledge transfer from larger instruct models.
- RLHF (Human Feedback): Aligns outputs with human preferences.
- RLMF (Machine Feedback): Boosts mathematical reasoning.
- RLEF (Execution Feedback): Enhances code accuracy by validating outputs against test cases.
The result? Gemma 3 scores 1338 on LMArena, outperforming competitors in its class.
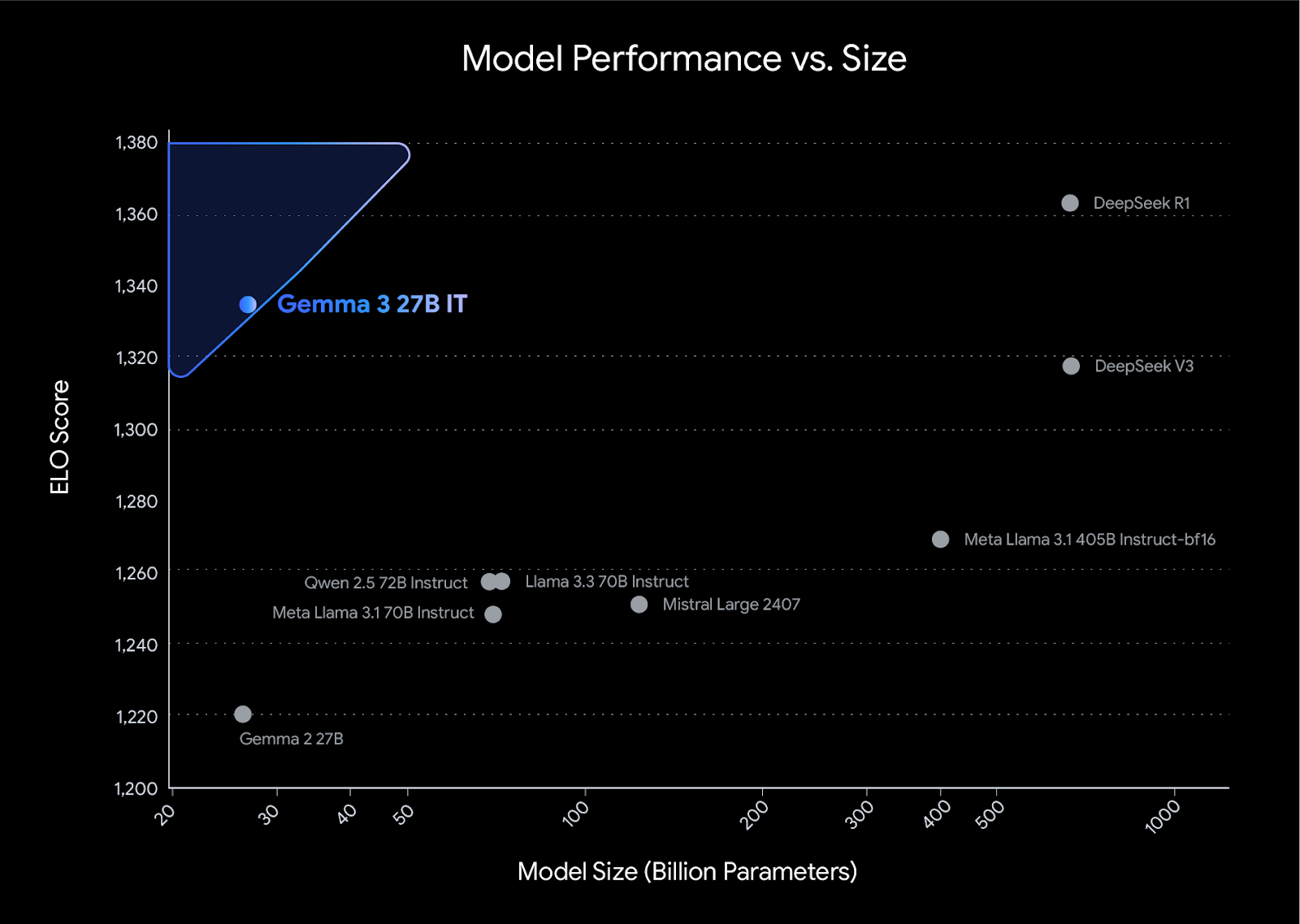
Gemma 3’s efficiency-to-performance ratio sets industry benchmarks.
Multimodality in Action: Code & Use Cases
Gemma 3’s flexible input format interleaves text and images. Here’s how it works:
Multi-Turn Dialogue Example
<bos><start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
Gemma<end_of_turn>
<start_of_turn>model
Gemma who?<end_of_turn>
Image + Text Interaction
<bos><start_of_turn>user
Image A: <start_of_image>
Image B: <start_of_image>
Label A: water lily
Label B:<end_of_turn>
<start_of_turn>model
Desert rose<end_of_turn>
ShieldGemma 2: Safeguarding AI Interactions
Safety is central to Gemma 3’s design. ShieldGemma 2, a 4B safety classifier, moderates both synthetic and natural images across categories like:
- Violence
- Hate speech
- Misinformation
Integrated seamlessly, it ensures ethical AI deployments without compromising performance.
The Gemmaverse: Community Innovations
The Gemma community continues to push boundaries:
- Princeton NLP: Developed SimPO, a fine-tuning method that skips reference models for faster alignment.
- INSAIT: Built state-of-the-art Bulgarian LLMs.
- Nexa AI: Trained Gemma on OmniAudio for audio processing.
Discover endless inspiration for your next project with Mobbin’s stunning design resources and seamless systems—start creating today! 🚀
Getting Started with Gemma 3: Your Roadmap
- Experiment: Test Gemma 3 instantly via Google AI Studio.
- Download: Access weights on Hugging Face or Kaggle.
- Integrate: Use frameworks like Hugging Face Transformers, Ollama, or Gemma.cpp.
- Deploy: Scale via Vertex AI, Cloud TPU, or edge devices.
Conclusion: The Future Is Multimodal
Gemma 3 isn’t just a tool—it’s a gateway to the next AI frontier. Whether you’re analyzing medical images, localizing apps for global markets, or building the next viral chatbot, Gemma 3 delivers the power and flexibility to innovate fearlessly.
Join the Gemmaverse today, and don’t forget to explore Mobbin for design inspiration that complements your AI journey. The future of AI is here—and it’s open, responsible, and limitless.










