
Meet Dagster - Cloud-native orchestration of data pipelines

Introduction
Dagster is a cloud-native data orchestration platform designed to streamline the development, production, and observation of data assets. As data pipelines become increasingly complex, the need for efficient orchestration tools that provide visibility, reliability, and scalability has grown. Dagster addresses these needs by offering a robust, Python-based framework that integrates seamlessly with modern data ecosystems.
In this comprehensive blog post, we will explore Dagster’s core features, its architecture, and its practical applications. Whether you are a data engineer, data scientist, or a DevOps professional, this guide will help you understand how Dagster can enhance your data workflows.
What is Dagster?
Dagster is a data orchestrator that allows you to define, execute, and monitor data pipelines. It models data workflows as a series of interconnected assets, enabling you to understand the relationships between different components of your data pipeline. This asset-centric approach simplifies debugging, ensures data quality, and enhances observability.
Key Features
- Declarative Programming Model: Define data assets and their dependencies using Python functions.
- Integrated Lineage and Observability: Track data flows and monitor pipeline execution in real-time.
- Testability: Facilitate unit testing and integration testing of data pipelines.
- Cloud-Native: Designed to scale with modern cloud infrastructure.
- Interoperability: Integrates with popular data tools and services.
Getting Started with Dagster
Installation
Dagster is available on PyPI and supports Python versions 3.8 through 3.12. To install Dagster, run:
pip install dagster dagster-webserver
This installs two packages:
dagster: The core programming model.dagster-webserver: The server hosting Dagster's web UI.
For detailed installation instructions, especially for specific environments like Mac with Apple silicon, refer to the installation guide.
Core Concepts
Before diving into code, it’s essential to understand Dagster’s core concepts:
- Assets: The primary building blocks representing data.
- Ops: Units of computation within a pipeline.
- Jobs: Compositions of ops defining a data workflow.
- Sensors and Schedules: Mechanisms to trigger jobs based on events or time.
Quickstart
To get hands-on experience, follow the quickstart guide. This guide walks you through setting up your first Dagster project, defining assets, and running a simple pipeline.
Defining Data Assets
In Dagster, data assets are defined using Python functions annotated with the @asset decorator. Here’s an example illustrating how to define and connect multiple assets:
from dagster import asset
from pandas import DataFrame, read_html, get_dummies
from sklearn.linear_model import LinearRegression
@asset
def country_populations() -> DataFrame:
df = read_html("https://tinyurl.com/mry64ebh")[0]
df.columns = ["country", "pop2022", "pop2023", "change", "continent", "region"]
df["change"] = df["change"].str.rstrip("%").str.replace("−", "-").astype("float")
return df
@asset
def continent_change_model(country_populations: DataFrame) -> LinearRegression:
data = country_populations.dropna(subset=["change"])
return LinearRegression().fit(get_dummies(data[["continent"]]), data["change"])
@asset
def continent_stats(country_populations: DataFrame, continent_change_model: LinearRegression) -> DataFrame:
result = country_populations.groupby("continent").sum()
result["pop_change_factor"] = continent_change_model.coef_
return result
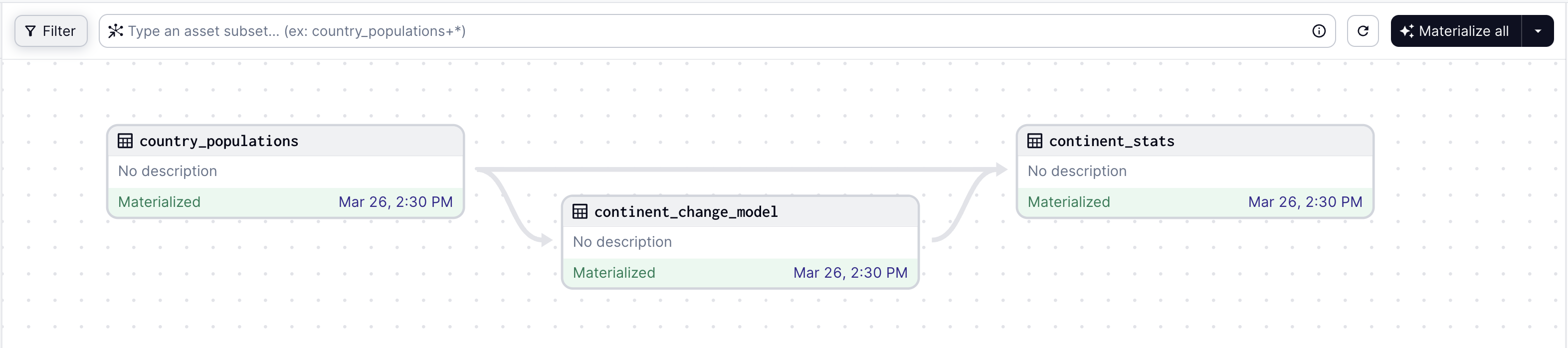
Asset Graph
The above code defines a graph of three interconnected assets:
country_populations: Fetches and processes population data.continent_change_model: Trains a linear regression model on the population change data.continent_stats: Aggregates population data and applies the regression model to compute statistics.
Dagster’s web UI visualizes these relationships, making it easier to understand data lineage and dependencies.
Orchestrating Data Pipelines
Dagster’s orchestration capabilities allow you to manage complex data workflows with ease. You can define jobs, schedules, and sensors to automate the execution of your pipelines.
Jobs
A job in Dagster is a collection of ops that define a data workflow. Here’s how to create a simple job:
from dagster import job
@job
def my_simple_job():
country_populations()
continent_change_model()
continent_stats()
Schedules and Sensors
Schedules and sensors automate job execution based on time or events. Here’s an example of a schedule that runs a job daily:
from dagster import schedule
@schedule(cron_schedule="0 0 * * *", job=my_simple_job)
def daily_schedule():
return {}
Sensors can trigger jobs based on external events, such as the arrival of new data files or changes in a database.
Running Jobs
You can run jobs directly from the Dagster web UI or programmatically using the Dagster API. The web UI provides detailed insights into job executions, including logs, metrics, and data lineage.
Integrations
Dagster integrates with a wide range of data tools and services, making it versatile for different data environments. Some popular integrations include:
- Databases: PostgreSQL, MySQL, SQLite
- Data Warehouses: Snowflake, BigQuery
- Data Processing: Spark, Dask, Pandas
- Machine Learning: TensorFlow, PyTorch, Scikit-learn
Example: Integrating with Snowflake
Here’s an example of how to integrate Dagster with Snowflake:
from dagster import asset, Config
import snowflake.connector
import pandas as pd
@asset(config_schema={"snowflake_conn": Config})
def fetch_snowflake_data(context) -> pd.DataFrame:
conn_params = context.op_config["snowflake_conn"]
conn = snowflake.connector.connect(**conn_params)
df = pd.read_sql("SELECT * FROM my_table", conn)
conn.close()
return df
Configuring Resources
Resources in Dagster allow you to manage external dependencies like databases, APIs, and message queues. Here’s how to define and configure a Snowflake resource:
from dagster import resource
@resource(config_schema={"user": str, "password": str, "account": str})
def snowflake_resource(init_context):
return snowflake.connector.connect(
user=init_context.resource_config["user"],
password=init_context.resource_config["password"],
account=init_context.resource_config["account"]
)
@asset(required_resource_keys={"snowflake"})
def fetch_data_from_snowflake(context):
conn = context.resources.snowflake
df = pd.read_sql("SELECT * FROM my_table", conn)
conn.close()
return df
Example: Integrating with TensorFlow
Dagster’s flexibility allows it to orchestrate machine learning workflows. Here’s an example of integrating Dagster with TensorFlow:
from dagster import asset
import tensorflow as tf
@asset
def train_model() -> tf.keras.Model:
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
return model
Advanced Features
Software-Defined Assets (SDAs)
SDAs are a core concept in Dagster that represent data assets produced by computations. SDAs provide a unifying abstraction for data teams, enabling easier collaboration and adherence to best practices. They also facilitate:
- Domain-Specific Languages (DSLs): Custom languages for defining data workflows.
- Continuous Integration: Automated testing and deployment of data pipelines.
- Local Development: Running and debugging pipelines on local machines.
Observability and Lineage
Dagster’s built-in observability tools provide detailed insights into data workflows. You can track the flow of data through your pipelines, monitor execution metrics, and diagnose issues. The web UI displays lineage graphs, execution logs, and performance metrics, helping you identify bottlenecks and optimize your pipelines.
Testing
Dagster emphasizes testability, allowing you to write unit tests and integration tests for your data pipelines. Here’s an example of a simple unit test:
from dagster import execute_pipeline, ModeDefinition
from my_pipeline import my_simple_job
def test_my_simple_job():
result = execute_pipeline(my_simple_job, mode_def=ModeDefinition())
assert result.success
Integration tests can simulate the entire data workflow, ensuring that all components work together as expected.
Community and Contribution
Dagster has a vibrant community of data practitioners who share knowledge, provide support, and contribute to the open-source project. You can join the community through the Dagster Slack and follow development updates on GitHub.
Contributing to Dagster
If you’re interested in contributing to Dagster, the project welcomes contributions from the community. Here’s how you can get started:
- Fork the repository on GitHub.
- Clone your fork and set up the development environment.
- Make your changes and write tests.
- Submit a pull request with a detailed description of your changes.
For detailed guidelines, refer to the contributing guide.
Conclusion
Dagster is a powerful and versatile tool for orchestrating data workflows. Its asset-centric approach, robust observability features, and seamless integrations make it an ideal choice for modern data teams. By adopting Dagster, you can streamline the development, execution, and monitoring of your data pipelines, ensuring data quality and reliability.
Whether you are building simple data transformations or complex machine learning pipelines, Dagster provides the tools and flexibility you need to succeed. Explore Dagster today and take your data workflows to the next level.
For more information and detailed documentation, visit the Dagster website and official documentation.










